Self-supervised learning (SSL) has emerged as a powerful paradigm for learning meaningful data representations without relying on human annotations. A dominant approach in this field is joint embedding self-supervised learning (JE-SSL), in which two networks are trained to produce similar embeddings for different views of the same image. Recent work has shown that effective JE-SSL methods produce representations that avoid dimensional collapse and promote uniformity.
To encourage such properties, we explore a simple, geometry-based regularizer.
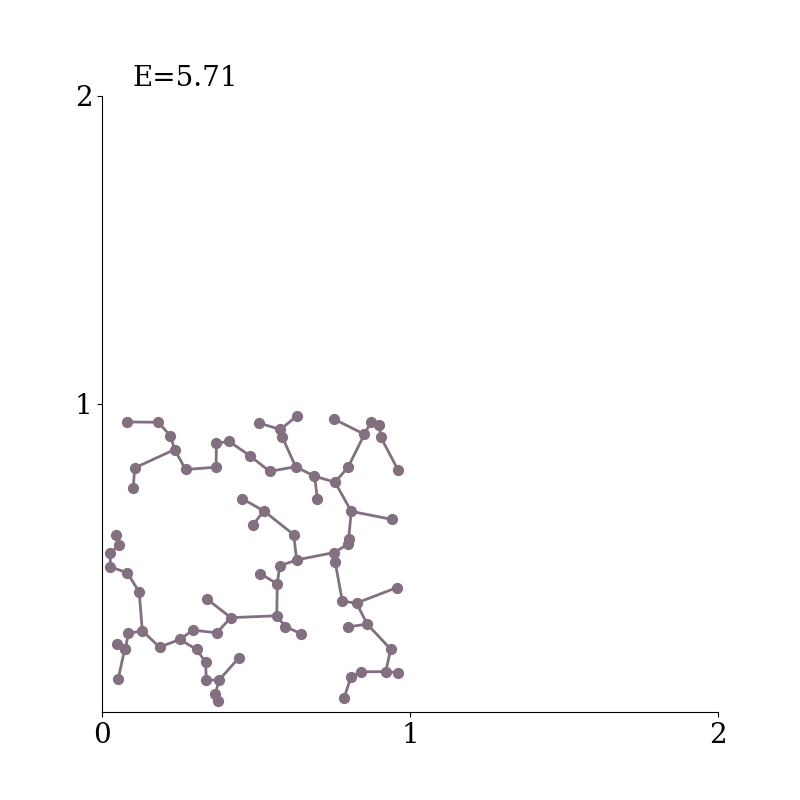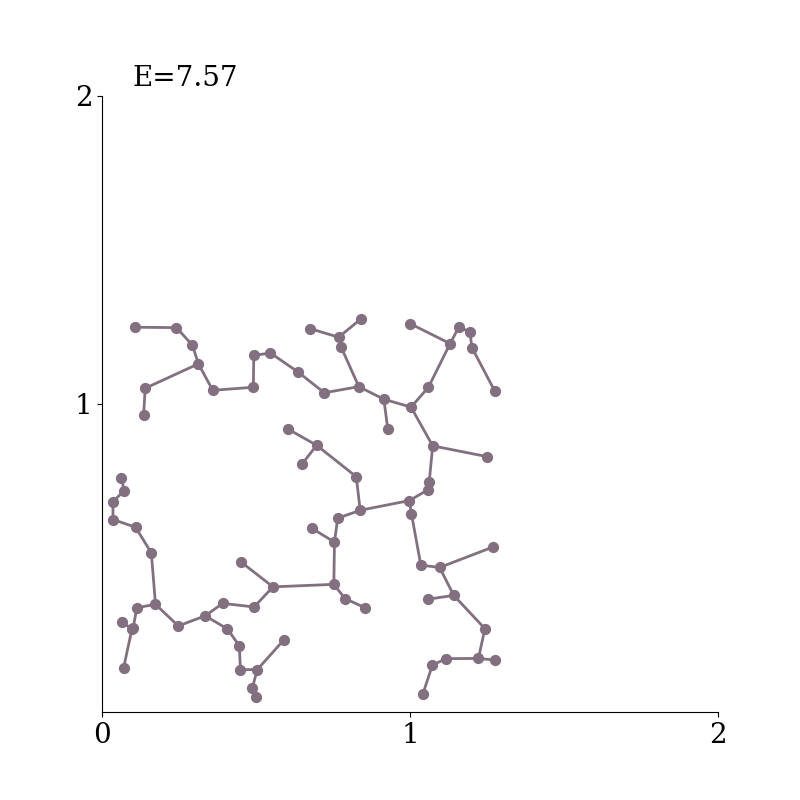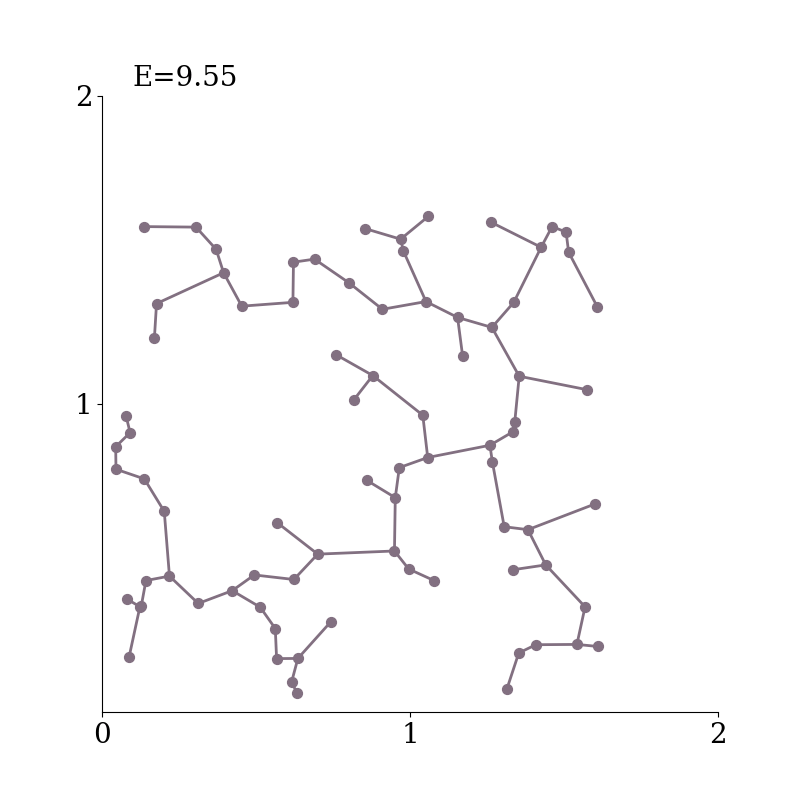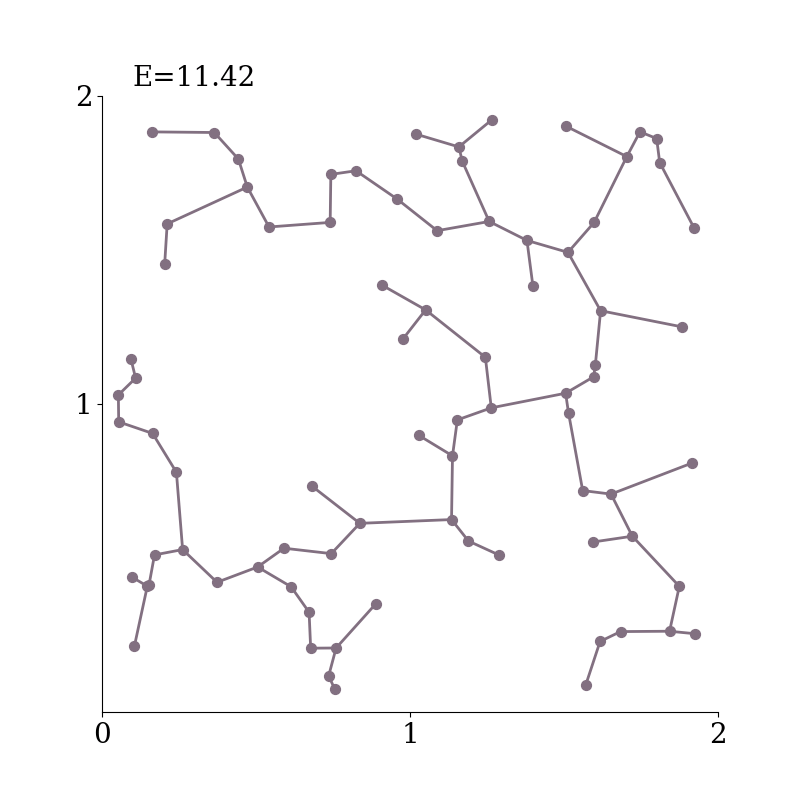
Specifically, we consider the Minimum Spanning Tree ($\mathrm{MST}$) of the embeddings--a tree that connects all the points together, without any cycles and with the minimum possible total edge length.
More precisely, for a point cloud $Z$, a spanning tree (ST) is an undirected graph $G=(V,E)$ on $Z$ that is connected and acyclic.
We define the length of $G$ as:
\begin{equation}
E(G) := \sum_{(z,z')\in E} \|z-z'\|_2
\label{eq:alpha_length}
\end{equation}
A minimum spanning tree of $Z$, denoted by $\mathrm{MST}(Z)$, is an spanning tree of $Z$ that minimizes length $E$.
Example of a minimum spanning tree in $2$-d.
$\mathrm{MST}(Z)$ connects the set of points $Z$ together, without any cycles and with the minimum possible total edge length.
As the $\mathrm{MST}(Z)$ connects all points together, increasing the distances between them naturally increases the total length of the $\mathrm{MST}$.
The length of the $\mathrm{MST}$ scales under any rescaling of $Z$.
Thus, maximizing the $\mathrm{MST}$ length alone would cause the points to spread out indefinitely. However, additionally constraining them to a compact manifold would encourage full use of the representation space and prevent trivial scaling.
Building on this idea, we propose T-REG, a regularizer that maximizes the $\mathrm{MST}$ length of embeddings while constraining them to the unit sphere.
Here, we present a intuitive view of this regularization, its connections to entropy-based statistical dimension estimation (Steele,1988) and its application to SSL: T-REGS.
T-REG: Minimum Spanning Tree based Regularization
T-REG has two terms, given $Z = \{z_1, ..., z_n\}\subseteq\mathbb{R}^d$, the set of $n$ embeddings of dimension $d$:
A length-maximization loss $\mathcal{L}_{\text{E}}$ that decreases with the length of the minimum spanning tree:
\begin{equation}
\mathcal{L}_{\text{E}}(Z) = - \frac{1}{n} \,\text{E}(\mathrm{MST}({Z})),
\end{equation}
where $\text{E}(\mathrm{MST}({Z}))$ denotes the length of the $\mathrm{MST}$ of $Z$.
A soft sphere-constraint $\mathcal{L}_{\text{S}}$ that increases with the distance to a fixed sphere $\mathbb{S}$, given by:
\begin{equation}
\mathcal{L}_\text{S}(Z) = \frac{1}{n} \sum_i (\Vert z_i\Vert_2 - 1)^2.
\end{equation}
These two terms combined force the embeddings to lie on $\mathbb{S}$ (or close to it), while spreading them out along $\mathbb{S}$.
Maximizing the MST length alone would cause the points to diverge to infinity; the sphere constraint prevents this by keeping the embeddings within a fixed region around $\mathbb{S}$.
The overall T-REG loss combines these two terms:
\begin{equation}\label{eq:TREG}
\mathcal{L}_{\text{T-REG}}(Z) = \gamma\, \mathcal{L}_{\text{E}}(Z) + \lambda\, \mathcal{L}_\text{S}(Z),
\end{equation}
where $\gamma$ and $\lambda$ are hyperparameters controlling the trade-off between spreading out the embeddings and maintaining them on the sphere.
Illustration of T-REG with synthetic data
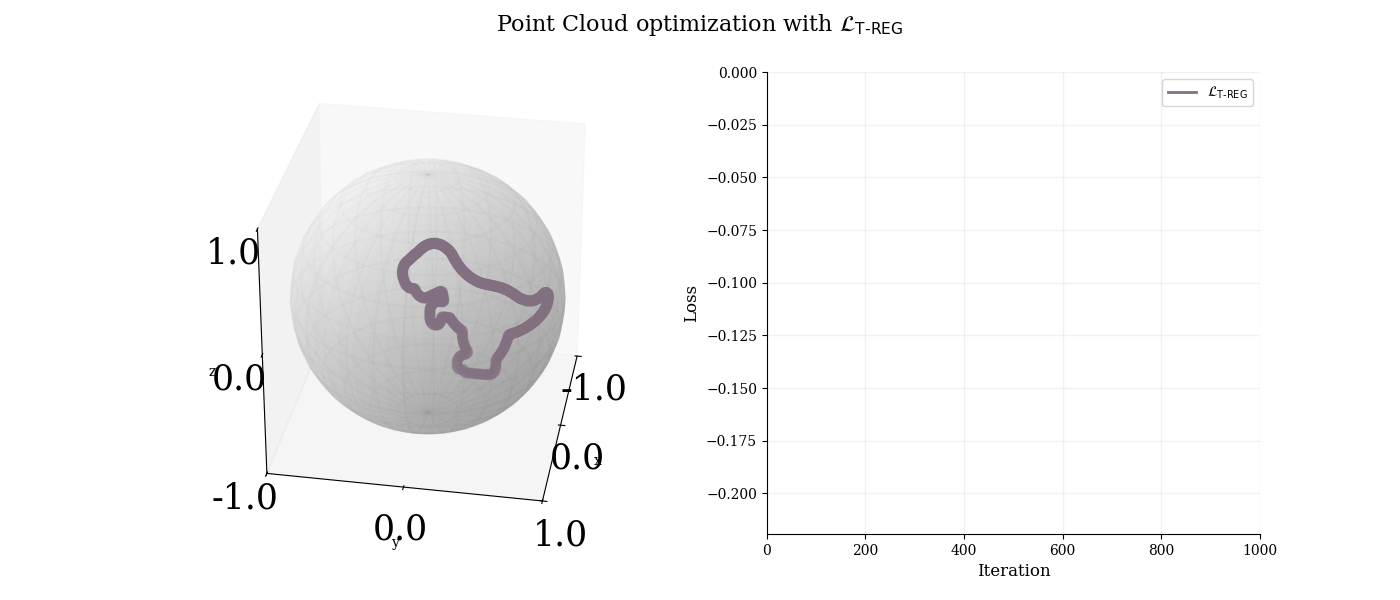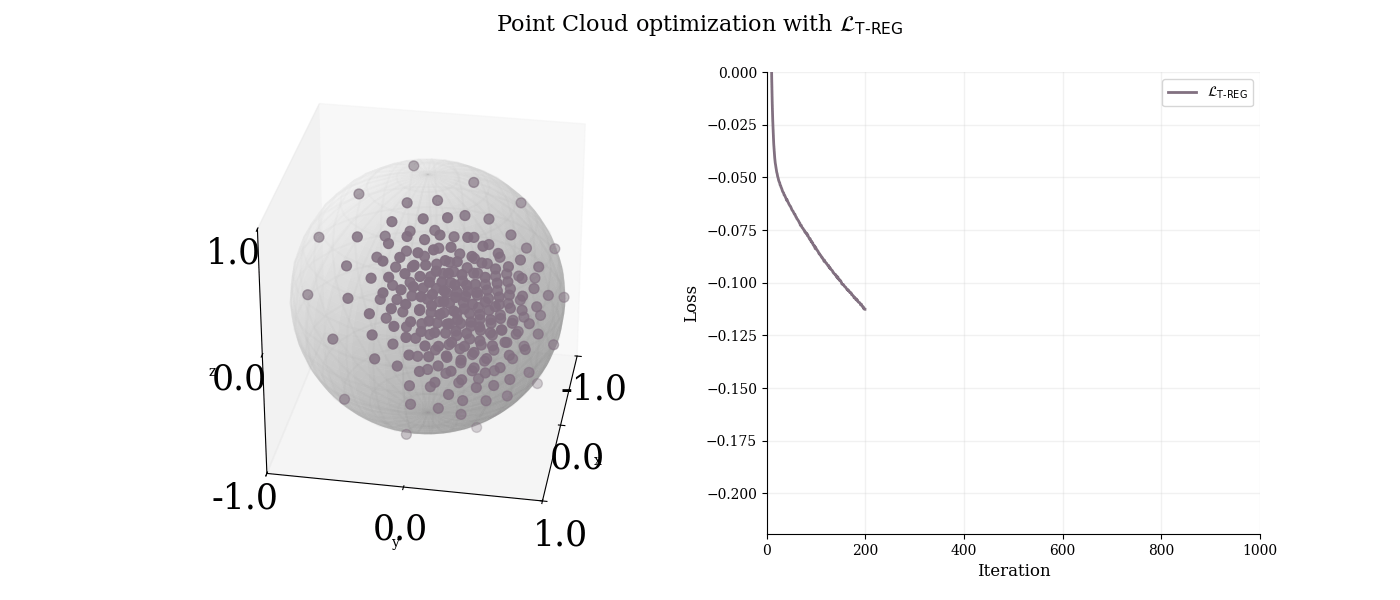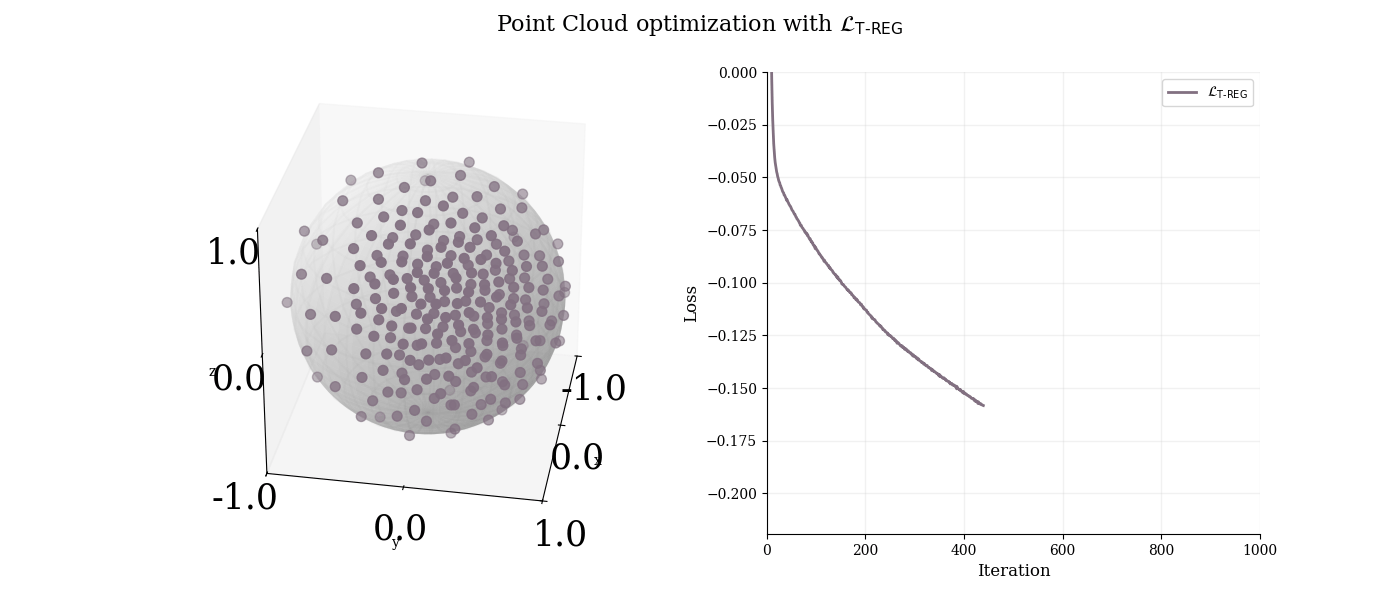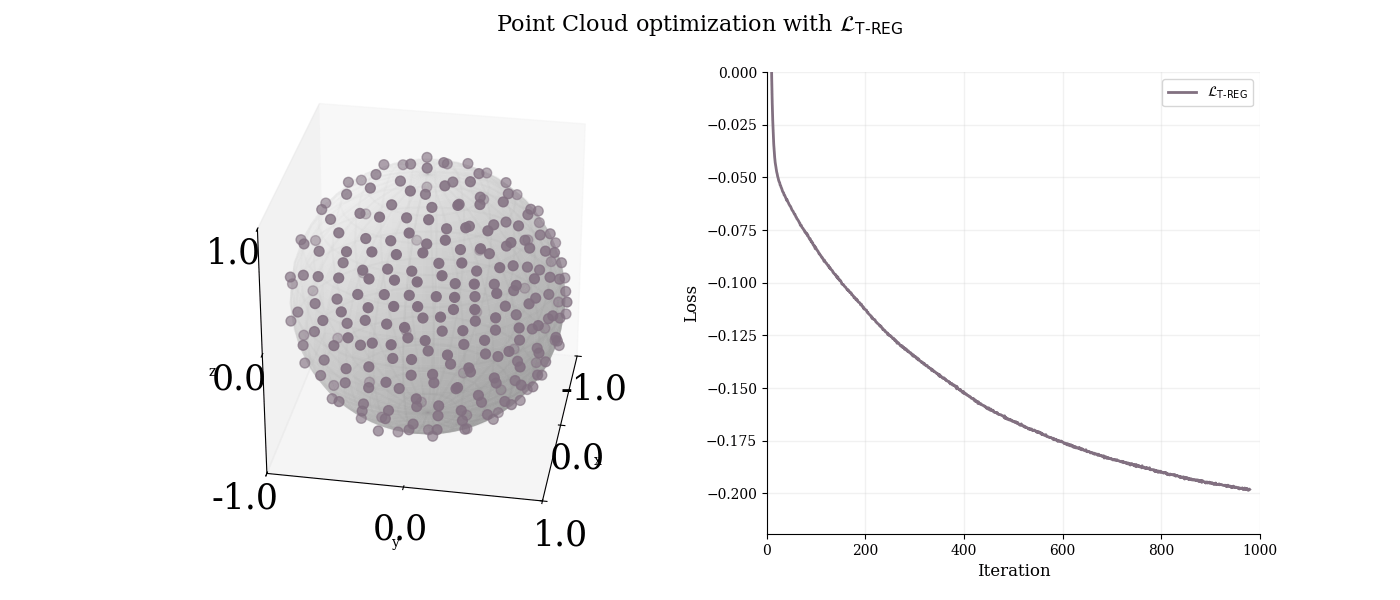
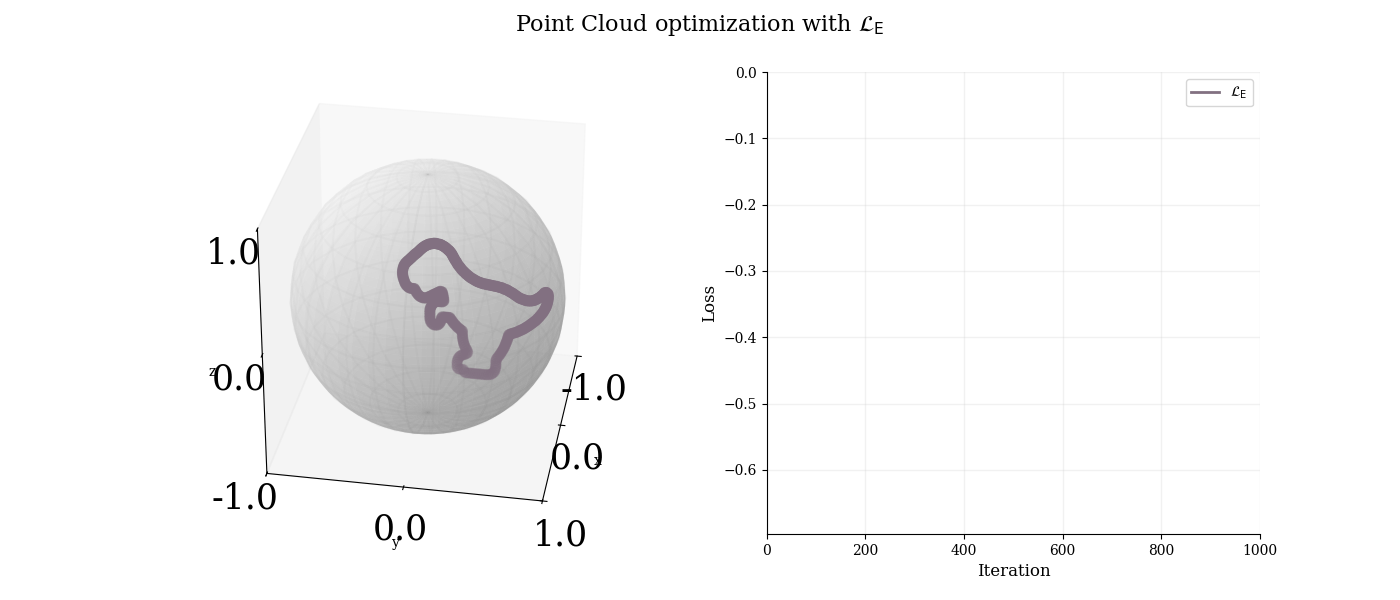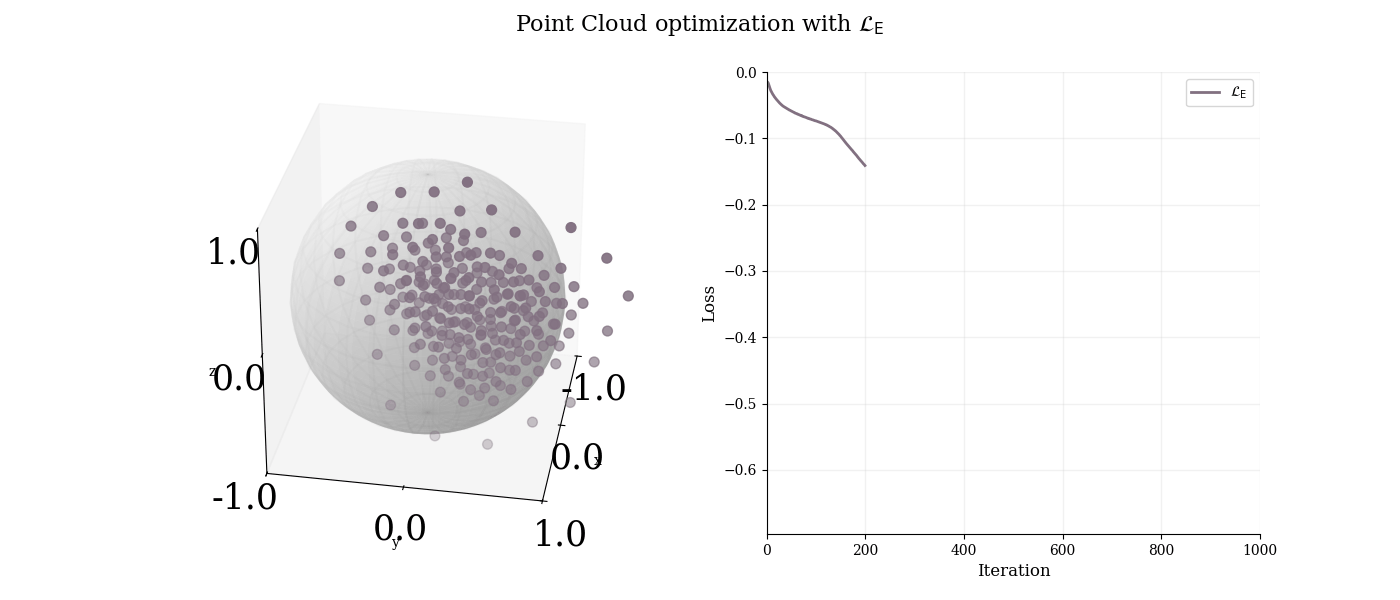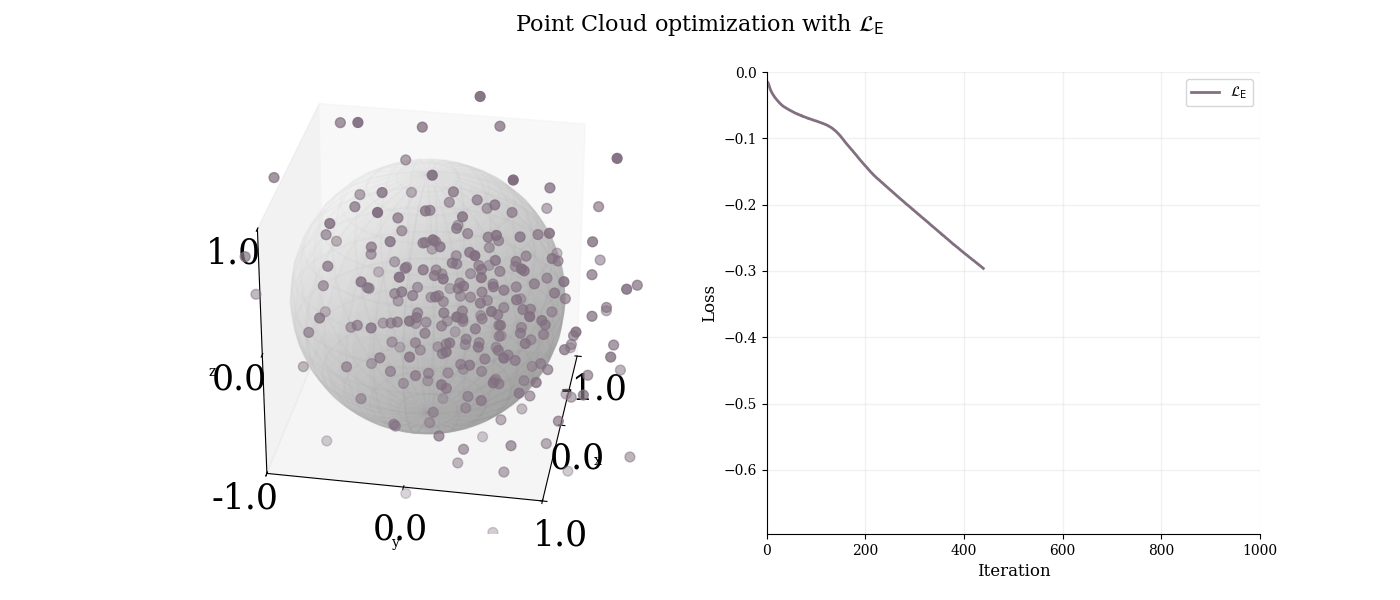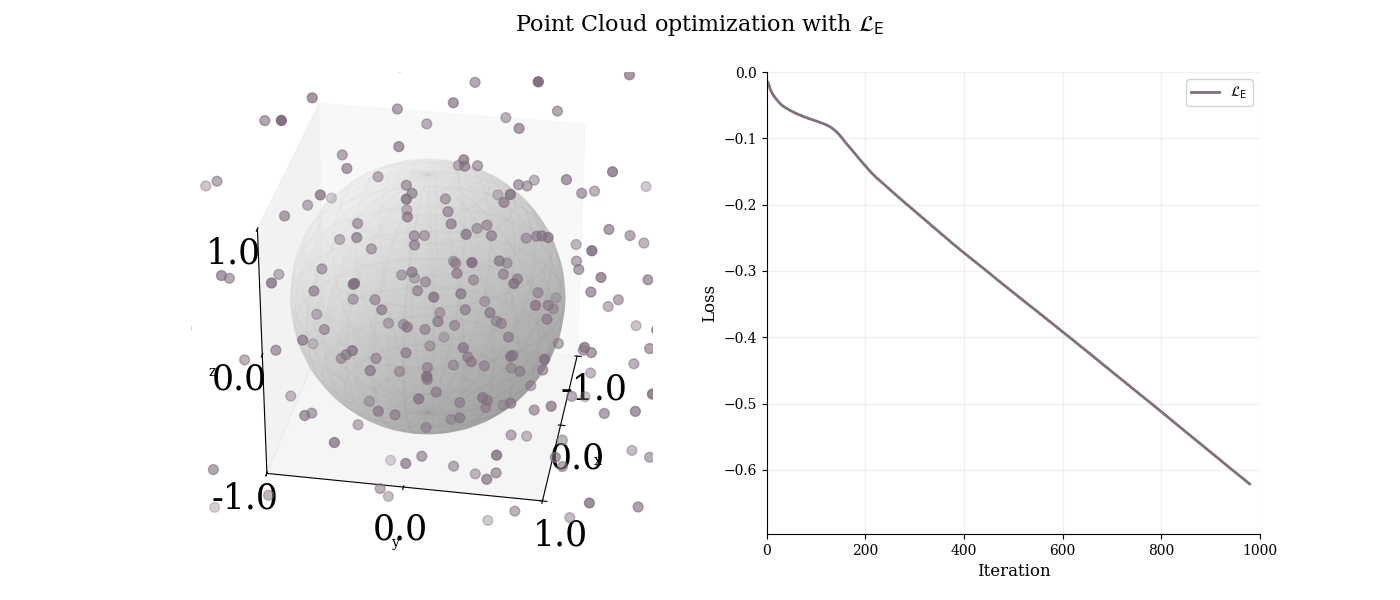
We apply T-REG alone to optimize a degenerate point cloud and analyze its behavior.
$3$-d point cloud analysis with T-REG. T-REG successfully spreads points uniformly on the sphere by combining MST length maximization and sphere constraint.
T-REG successfully spreads points uniformly on the sphere.
However, without the sphere constraint, the points diverge to infinity, as shown below:
$3$-d point cloud analysis with $\mathcal{L}_{\text{E}}$. Using only MST length maximization leads to excessive dilation.
Theoretical Analysis
1. Behavior on small samples
We begin by considering the case where $n\le d+1$. It is particularly relevant since, in SSL, batch sizes are often smaller than or comparable to the ambient dimension. In order to account for the effect of the soft sphere constraint, we assume the points of $X$ lie inside some fixed closed Euclidean $d$-ball ${B}$ of radius $r$ centered at the origin.
Theorem 1: Under the above conditions, the maximum of $\text{E}({X})$ over the point sets $X\subset{B}$ of fixed cardinality $n$ is attained when the points of $X$ lie on the sphere ${S}=\partial{B}$, at the vertices of a regular $(n-1)$-simplex that has ${S}$ as its smallest circumscribing sphere.
Theorem 1 explains the behavior of T-REG as follows: first, minimizing the term $\mathcal{L}_{\text{E}}$ in expands the point cloud until the sphere constraint term $\mathcal{L}_{\text{S}}$ becomes the dominating term (which happens eventually since $\mathcal{L}_{\text{S}}$ grows quadratically with the scaling factor, versus linearly for $\mathcal{L}_{\text{E}}$); at that stage, the points stop expanding and start spreading themselves out uniformly along the sphere of directions. The amount of expansion before spreading is prescribed by the strength of the sphere constraint term versus the term in the loss, which is driven by the ratio between their respective mixing parameters $\lambda$ and $\gamma$.
2. Asymptotic behavior on large samples
We now consider the case where $n> d+1$, focusing specifically on the asymptotic behavior as $n\to\infty$. We analyze the constant $C$ in Theorem 1 of (Steele, 1988), which can be made independent of the density of the sampling $X$. This, in particular, allows us to show that uniform and dimension-maximizing densities are asymptotically optimal for $E(\mathrm{MST}(\cdot))$. We fix a compact Riemannian $d$-manifold, $\mathcal{M}$, equipped with the $d$-dimensional Hausdorff measure $\mu$.
Theorem 2,(Costa et Hero, 2006): Let $X_n$ be an iid $n$-sample of a probability measure on $\mathcal{M}$ with density $f_X$ w.r.t. $\mu$. Then, there exists a constant $C'$ independent of $f_X$ and of $\mathcal M$ such that:
\begin{equation}
n^{-\frac {d-1}{d}} \cdot \text{E}(X_n) \xrightarrow[n\to \infty]{}{C' \int f_X^{\frac{d-1}{d}}}\mathrm{d} \mu
\quad
\textnormal{almost surely.}
\end{equation}
As pointed out by (Costa et Hero, 2006),
the limit in Theorem 2 is related to theintrinsic Rényi $\frac{d-1}{d}$-entropy:
\begin{equation}
\varphi_{\frac{d-1}{d}}(f) = \frac{1}{1-\frac{d-1}{d}} \log \int f^{\frac{d-1}{d}}\mathrm{d}\mu,
\end{equation}
which is known to converge to the Shannon entropy as $\frac{d-1}{d}\to
1$ (Shannon Entropy, Renyi Entropy, and Information. Bromiley et al., 2004). The Shannon entropy (Maximum Entropy Autoregressive Conditional Heteroskedasticity Model. Park et al., 2009), in turn, achieves its maximum at the
uniform distribution on compact sets (Maximum Entropy Autoregressive Conditional Heteroskedasticity Model. Park et al., 2009).
T-REGS: T-REG for SSL
Overview of T-REGS.(Left) Two augmented views $X, X'$ are encoded by $f_\theta$ and projected by $h_\phi$ into embeddings $Z, Z'$. Training jointly: (i) enforces view invariance via $\mathcal{L}_\text{SSL}(Z,Z')$ (MSE when used as a standalone regularizer, or a standard SSL loss when used as an auxiliary term); (ii) maximizes the minimum-spanning-tree length on each branch, $\mathcal{L}_\mathrm{E}(Z)$ and $\mathcal{L}_\mathrm{E}(Z')$, repelling edge-connected points in $\mathrm{MST}(Z)$ and $\mathrm{MST}(Z')$; and (iii) applies sphere constraints $\mathcal{L}_\mathrm{S}(Z)$ and $\mathcal{L}_\mathrm{S}(Z')$.
(Right) As a result, T-REGS induces uniformely distributed embeddings without dimensional collapse.
T-REGS extend T-REG to self-supervised learning (SSL).
For an input image $i$, two transformations $t,t'$ are sampled from a distribution $\mathcal{T}$ to produce two augmented views $x=t(i)$ and $x'=t'(i)$.
These transformations are typically random crops and color distortions.
We compute embeddings $z=h_\phi(f_\theta(x))$ and $z'=h_\phi(f_\theta(x'))$ using a backbone $f_\theta$ and projector $h_\phi$.
T-REGS acts as a regularization applied separately to the embedding batches $Z=[z_1, ..., z_n]$ and $Z'=[z'_1, ..., z'_n]$.
Specifically, embeddings from each view batch, $Z$ and $Z'$, are treated as points in a high-dimensional space,
and Kruskal's algorithm is used to construct two Minimum Spanning Tree (MST), one for each view batch.
These MSTs yield two T-REG regularization terms, which are combined into the T-REGS objective as follows:
\begin{align}
\mathcal{L}_{\text{T-REGS}}(Z,Z') =
\underbrace{\gamma \, \mathcal{L}_\text{E}(Z) + \lambda \, \mathcal{L}_\text{S}(Z)}_{\mathcal{L}_\text{T-REG}(Z)} + \underbrace{\gamma \, \mathcal{L}_\text{E}(Z') + \lambda \, \mathcal{L}_\text{S}(Z')}_{\mathcal{L}_\text{T-REG}(Z')}.
\label{eq:loss}
\end{align}
where $\gamma, \lambda$ control the contribution of each term.
In practice, T-REGS can be used as:
A standalone regularization, combined directly with an invariance term such as the Mean Squared Error:
$$\mathcal{L}(Z,Z') = \beta \, \mathcal{L}_\text{MSE}(Z,Z') + \mathcal{L}_\text{T-REGS}(Z,Z')$$
where $\mathcal{L}_\text{MSE}(Z,Z') = \frac{1}{n} \sum_i \|z_i - z'_i\|_2^2$ and $\beta$ is a mixing parameter.
As an auxiliary loss to existing SSL methods:
$$\mathcal{L}(Z,Z') = \beta \, \mathcal{L}_{\text{SSL}}(Z,Z') + \mathcal{L}_\text{T-REGS}(Z,Z')$$
where $\mathcal{L}_{\text{SSL}}(Z,Z')$ denotes the objective function of a given SSL method, and $\beta$ is a mixing parameter.
Bibtex
@inproceedings{
mordacq2025tregs,
title={T-{REGS}: Minimum Spanning Tree Regularization for Self-Supervised Learning},
author={Julie Mordacq and David Loiseaux and Vicky Kalogeiton and Steve Oudot},
booktitle={The Thirty-ninth Annual Conference on Neural Information Processing Systems},
year={2025},
}
Acknowledgements
This work was partially supported by Inria Action Exploratoire PreMediT (Precision Medicine using Topology). We were granted access to the HPC resources of IDRIS under the allocations 2025-AD011016121 and 2025-AD011016483 made by GENCI.